



Back when I was a wee lad with a very security-compromised MySQL installation, I used to answer every web request with multiple “SELECT *” database requests — give me all the data and I’ll figure out what to do with it myself.
Today in a modern, data-intensive org, “SELECT *” will kill you. With petabytes of information, tens of thousands of tables (on the small side!), and millions and perhaps billions of calls flung at the database server, data science teams can no longer just ask for all the data and start working with it immediately.
Big data has led to the rise of data warehouses and data lakes (and apparently data lake houses), infrastructure to make accessing data more robust and easy. There is still a cataloguing and discovery problem though — just because you have all of your data in one place doesn’t mean a data scientist knows what the data represents, who owns it, or what that data might affect in the myriad of web and corporate reporting apps built on top of it.
That’s where Select Star comes in. The startup, which was founded about a year ago in March 2020, is designed to automatically build out metadata within the context of a data warehouse. From there, it offers a full-text search that allows users to quickly find data as well as “heat map” signals in its search results which can quickly pinpoint which columns of a dataset are most used by applications within a company and have the most queries that reference them.
The product is SaaS, and it is designed to allow for quick onboarding by connecting to a customer’s data warehouse or business intelligence (BI) tool.
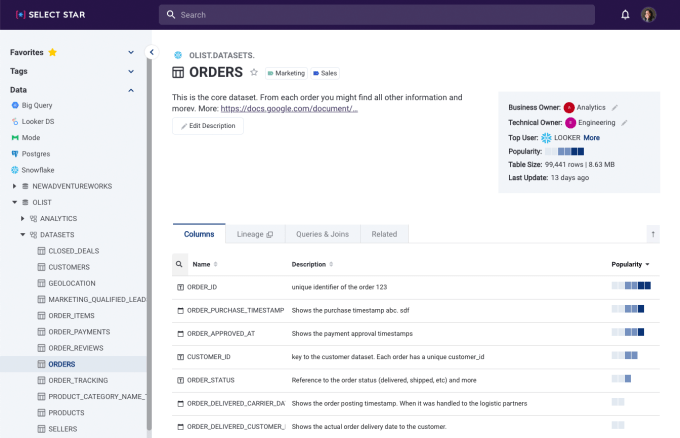
Select Star’s interface allows data scientists to understand what data they are looking at. Photo via Select Star.
Shinji Kim, the sole founder and CEO, explained that the tool is a solution to a problem she has seen directly in corporate data science teams. She formerly founded Concord Systems, a real-time data processing startup that was acquired by Akamai in 2016. “The part that I noticed is that we now have all the data and we have the ability to compute, but now the next challenge is to know what the data is and how to use it,” she explained.


She said that “tribal knowledge is starting to become more wasteful [in] time and pain in growing companies” and pointed out that large companies like Facebook, Airbnb, Uber, Lyft, Spotify and others have built out their own homebrewed data discovery tools. Her mission for Select Star is to allow any corporation to quickly tap into an easy-to-use platform to solve this problem.
The company raised a $2.5 million seed round led by Bowery Capital with participation from Background Capital and a number of prominent angels including Spencer Kimball, Scott Belsky, Nick Caldwell, Michael Li, Ryan Denehy and TLC Collective.
Data discovery tools have been around in some form for years, with popular companies like Alation having raised tens of millions of VC dollars over the years. Kim sees an opportunity to compete by offering a better onboarding experience and also automating large parts of the workflow that remain manual for many alternative data discovery tools. With many of these tools, “they don’t do the work of connecting and building the relationship,” between data she said, adding that “documentation is still important, but being able to automatically generate [metadata] allows data teams to get value right away.”

Select Star’s team, with CEO and founder Shinji Kim in top row, middle. Photo via Select Star.
In addition to just understanding data, Select Star can help data engineers begin to figure out how to change their databases without leading to cascading errors. The platform can identify how columns are used and how a change to one may affect other applications or even other datasets.
Select Star is coming out of private beta today. The company’s team currently has seven people, and Kim says they are focused on growing the team and making it even easier to onboard users by the end of the year.








{kind=link}