


Hightouch, a SaaS service that helps businesses sync their customer data across sales and marketing tools, is coming out of stealth and announcing a $2.1 million seed round. The round was led by Afore Capital and Slack Fund, with a number of angel investors also participating.
At its core, Hightouch, which participated in Y Combinator’s Summer 2019 batch, aims to solve the customer data integration problems that many businesses today face.
During their time at Segment, Hightouch co-founders Tejas Manohar and Josh Curl witnessed the rise of data warehouses like Snowflake, Google’s BigQuery and Amazon Redshift — that’s where a lot of Segment data ends up, after all. As businesses adopt data warehouses, they now have a central repository for all of their customer data. Typically, though, this information is then only used for analytics purposes. Together with former Bessemer Ventures investor Kashish Gupta, the team decided to see how they could innovate on top of this trend and help businesses activate all of this information.

HighTouch co-founders Kashish Gupta, Josh Curl and Tejas Manohar.
“What we found is that, with all the customer data inside of the data warehouse, it doesn’t make sense for it to just be used for analytics purposes — it also makes sense for these operational purposes like serving different business teams with the data they need to run things like marketing campaigns — or in product personalization,” Manohar told me. “That’s the angle that we’ve taken with Hightouch. It stems from us seeing the explosive growth of the data warehouse space, both in terms of technology advancements as well as like accessibility and adoption. […] Our goal is to be seen as the company that makes the warehouse not just for analytics but for these operational use cases.”


It helps that all of the big data warehousing platforms have standardized on SQL as their query language — and because the warehousing services have already solved the problem of ingesting all of this data, Hightouch doesn’t have to worry about this part of the tech stack either. And as Curl added, Snowflake and its competitors never quite went beyond serving the analytics use case either.
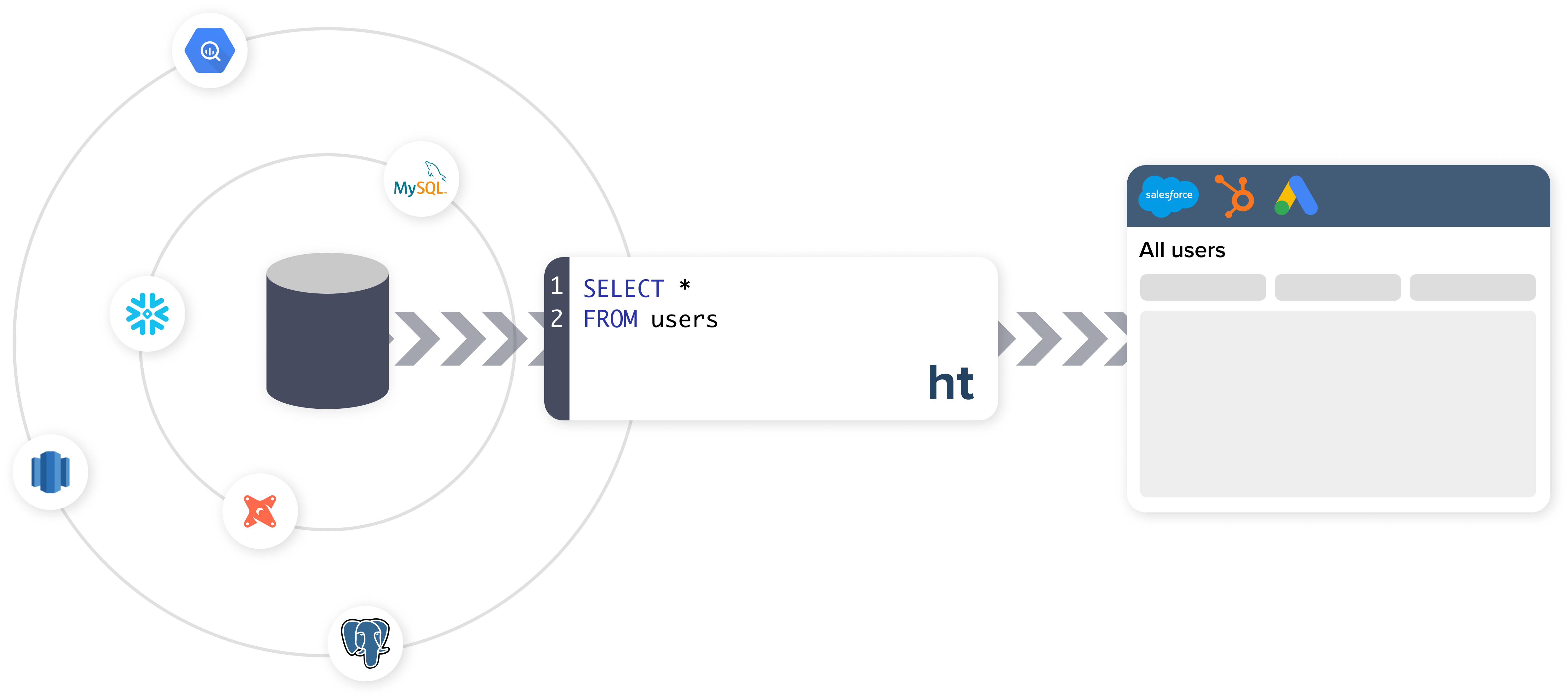
Image Credits: Hightouch
As for the product itself, Hightouch lets users create SQL queries and then send that data to different destinations — maybe a CRM system like Salesforce or a marketing platform like Marketo — after transforming it to the format that the destination platform expects.
Expert users can write their own SQL queries for this, but the team also built a graphical interface to help non-developers create their own queries. The core audience, though, is data teams — and they, too, will likely see value in the graphical user interface because it will speed up their workflows as well. “We want to empower the business user to access whatever models and aggregation the data user has done in the warehouse,” Gupta explained.
The company is agnostic to how and where its users want to operationalize their data, but the most common use cases right now focus on B2C companies, where marketing teams often use the data, as well as sales teams at B2B companies.

Image Credits: Hightouch
“It feels like there’s an emerging category here of tooling that’s being built on top of a data warehouse natively, rather than being a standard SaaS tool where it is its own data store and then you manage a secondary data store,” Curl said. “We have a class of things here that connect to a data warehouse and make use of that data for operational purposes. There’s no industry term for that yet, but we really believe that that’s the future of where data engineering is going. It’s about building off this centralized platform like Snowflake, BigQuery and things like that.”
“Warehouse-native,” Manohar suggested as a potential name here. We’ll see if it sticks.
Hightouch originally raised its round after its participation in the Y Combinator demo day but decided not to disclose it until it felt like it had found the right product/market fit. Current customers include the likes of Retool, Proof, Stream and Abacus, in addition to a number of significantly larger companies the team isn’t able to name publicly.









{kind=link}